
Most people think of Big Data as being about volume, but there are other critical dimensions such as velocity and variety. In some cases, volume is certainly important, but the main driver of business value comes from looking across many disparate sources – both internal and external. A unified view is essential to making this happen.
Most people think of Big Data as being about volume, but there are other critical dimensions such as velocity and variety. In some cases, volume is certainly important, but the main driver of business value comes from looking across many disparate sources – both internal and external. A unified view is essential to making this happen.
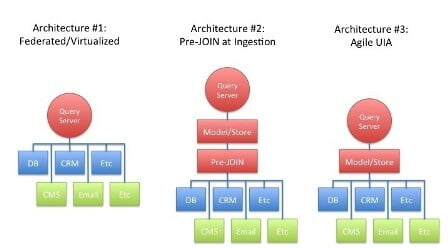
Architecturally, there are a few different routes to achieve unified information access (UIA) across silos. The following diagram presents the three most prevalent options.

- Federated or virtualized approach. A client calls a Query Server and provides details on the information it needs. The Query Server connects to each of many sources, both structured and unstructured, passes the query off to each source, and then aggregates the results and returns them to the client. It’s complex to build a model like this, though it seems sensible when first examined because it doesn’t require any normalization. On the other hand, it is also a “brute force” approach that won’t perform well on cross-silo analysis when any result set is large.
- Pre-JOINed approach. Data is ingested and normalized into a single model following an ETL process. A Query Server then resolves queries against it. This model will be more consistent with respect to performance. However, it trades-off flexibility at query time because in order for a new relationship to be used, all of the data must be re-ingested and re-normalized. The ingestion logic is also challenging IAS data must be modeled prior to ingestion, and the keys between data items must be pre-defined.
- True agile UIA approach. Data is ingested and modeled just as it was in the source repository – typically in tables with keys identifying relationships. Flat repositories like file systems become tables also. This model is consistent with respect to performance, and offers complete flexibility at query time as any relationship, even one that is not formal in the data can be used. The ingestion logic is far simpler than in option #2, as it does not require a normalized model and thus avoids the ETL step.
Selecting one of these architectures depends heavily on the use case. For solutions that simply need to aggregate information from multiple sources, architecture #1 can be made to work, especially if most of the data is structured. Solutions that require relational algebra might try approach #2 if there are relatively few sources, with limited growth of sources over time (it seems to work particularly well for eCommerce sites where the catalog is central to the experience). Architecture #3 is most suited for integrating multiple silos, at scale, across multiple domains, or for solutions that may support numerous types of analysis.
If you have an upcoming strategic project, use a UIA architecture. This will get your organization and colleagues thinking about how they can build solutions that connect the dots, instead of just creating more silos that require costly and time-consuming integration efforts.





{kind=link}