



I was at DataWeek/API World in mid-September 2014 (last week at the time of this writing) and saw some interesting things, almost entirely around Big Data. The two items that stood out for me, were the Graph DataBase system Neo4j (which I wish I had time and a reason to dig into more), and SiSense, who absolutely blew my mind.
I was at DataWeek/API World in mid-September 2014 (last week at the time of this writing) and saw some interesting things, almost entirely around Big Data. The two items that stood out for me, were the Graph DataBase system Neo4j (which I wish I had time and a reason to dig into more), and SiSense, who absolutely blew my mind.
Ever since I first heard of Hadoop and researched it, it seemed like a very poor solution. Way too much work, detached data, not real time, reliant on IT to put their queries together, etc.. SiSense saw this issue as well, but they addressed it in a totally different, two pronged approach. This isn’t a product review, but rather an overview of the technology and possibilities. SiSense is a provider of Business Intelligence (BI) technology, that includes a back-end powered by “in-chip” technology that easily enables non-techies to access and analyze large data sets from multiple sources, and a front-end for creating dashboards and reports that will display on any device, including mobile. I’m going to focus on the former.

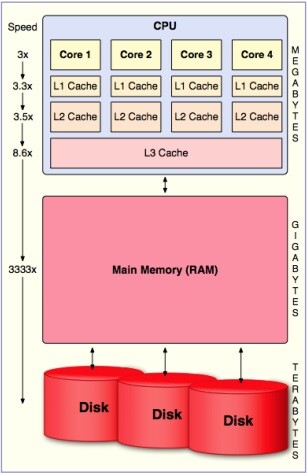
BI applications typically process and extraordinarily large amount of data to provide useful feedback in an easily digestible fashion. Because of that, they tend to be fairly slow as there is a constant stream of data from disk to memory to the CPU. Many vendors process as much in RAM as possible to speed things up, but this requires lots and lots of RAM. To make more efficient use of the RAM, pretty much all the BI vendors are using columnar databases as the staging area, this is about as efficient as you can get with your result set as you drop the data you don’t need.
This is where SiSense diverges from the crowd and how they can declare they can process 100 times the data at 10 times the speed of the competition. SiSense leaves that data on the disk instead of trying to jam it into RAM, then compresses the heck out of it.
Now here is where their secret sriracha sauce comes in: They do the decompression in the CPU cache.
As you can see from our graphic, even the L3 cache of the CPU is orders of magnitude faster than even doing it in RAM, and because the data is all highly compressed, it is moving off disk and through RAM at a significantly faster pace than could normally be achieved.
The application doing all this work is Prism, and it doesn’t stop there. Prism is holding a memory map of the current location of all data. When it process data or does any type of calculation, it is applying vector algebra to the data, thus enabling Prism to take advantage of the x86 in-chip Single Instruction Multiple Data (SIMD) vector instructions. This allows short arrays of data to be processed by a single instruction. As a result, the CPU cores are able to process data much faster and in parallel.
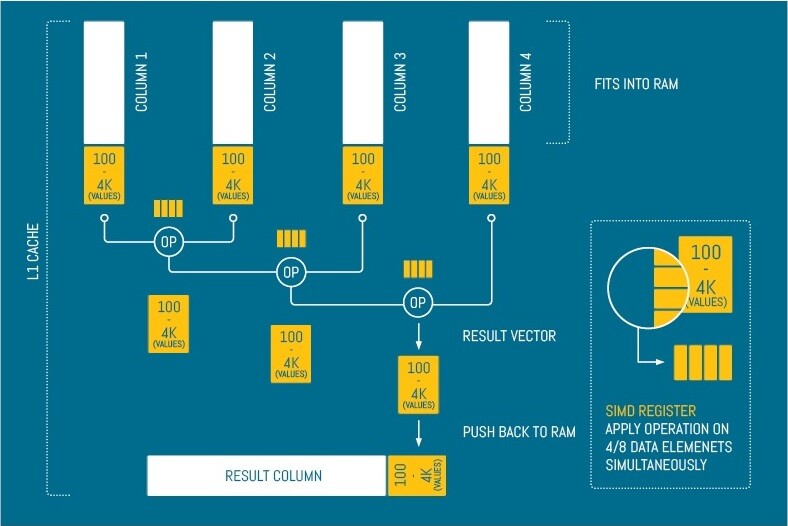



CPUs just get more and more powerful, with more cores and presumably, more cache. The technology that SiSense has created is about as durable as it gets in terms of future proofing. Nearly three quintillion bytes of data are created every day; 80 percent of it is unstructured, and only 20 percent of it is available to be processed.


The need for tools to effectively dig through all that data and present useful results is clear, and there are many vendors providing them, but SiSense, in my opinion, is genuinely addressing it the way it needs to be addressed.


{kind=link}