

We’re living in an era of digital switch-over with only one constant – evolve. And that digital transformation is being introduced by high-tech solutions. Hence, it comes as no surprise that mundane business tasks are being completely taken over by tech advancements. Machines, artificial intelligence (AI), and unsupervised learning are reshaping the way businesses vie for a place under the sun. With that being said, let’s have a closer look at how unsupervised machine learning is omnipresent in all industries.
- What Is Unsupervised Machine Learning?
- Unsupervised ML: The Basics
- Clustering – Exploration of Data
- Dimensionality Reduction – Modifying Data
- Unsupervised ML Algorithms: Real Life Examples
- Hidden Markov Model – Pattern Recognition, Bioinformatics, Data Analytics
- DBSCAN Clustering – Market research, Data analysis
- Principal Component Analysis (PCA) – Face recognition, Recommendation systems
- t-SNE – Non-linear Visualization Method
- Singular Value Decomposition (SVD) – Recommender Systems
- Association Rule – Market basket analysis
What Is Unsupervised Machine Learning?
If you’ve ever come across deep learning, you might have heard about two methods to teach machines: supervised and unsupervised.
Imagine you put together an IKEA couch. You can do it in several ways, but the result should always be the same and that is a completed coach. Some ways make more sense than others, too. It’s nice to have an instruction manual and follow predefined steps. But if you are an experienced furniture assembler, you can toss the manual aside.
Well, machine learning is almost the same. If you have labeled training data that you can use as a training example, we’ll call it supervised machine learning. However, if you have no pre-existing labels and need to organize a dataset, that’d be called unsupervised machine learning.

Unsupervised ML: The Basics
Unlike supervised ML, we do not manage the unsupervised model. Instead, we let the system discover information and outline the hidden structure that is invisible to our eye. Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets.
As a result, unsupervised ML algorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes.
The unsupervised ML algorithms are used to:
- Find groups or clusters;
- Perform density estimation;
- Reduce dimensionality.
Overall, unsupervised algorithms get to the point of unspecified data bits.
In this regard, unsupervised learning falls into two groups of algorithms – clustering and dimensionality reduction.
Clustering – Exploration of Data
Cluster analysis is aimed at classifying objects into groups called clusters on the basis of the similarity criteria. The main difference of clustering from the classification is that the list of groups is not clearly defined and is made sense in the process of algorithm operation.
The clustering process can be divided into the following stages:
- Selecting objects for clustering;
- Determining the set of variables;
- Calculating the similarity measure values between objects;
- Grouping similar objects into clusters;
- Presenting results.
Clustering methods are among the simplest algorithms used in unsupervised ML. Nevertheless, they can help fetch valuable data insights.
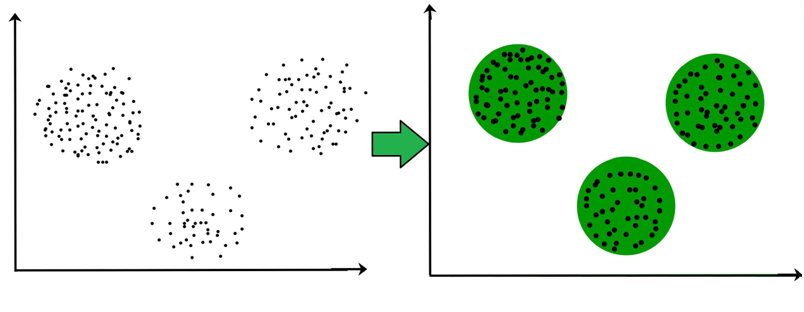
Clustering is a go-to grouping method in various industries:
- Marketing and sales – for predicting customer behavior (personalization and targeting).
- Search engines – for providing the needed search result.
- Academics – for monitoring the progress of students’ academic performance.
Overall, clustering is a common technique for statistical data analysis applied in many areas.
Dimensionality Reduction – Modifying Data
Have you ever struggled to get through a dataset with 30k+ variables? We have, and it’s a hell of a task. Missing values, erroneous, and irrelevant information throw off balance and thwart data interpretation.
Dimensionality reduction minimizes the number of features while retaining meaningful properties of the original information.
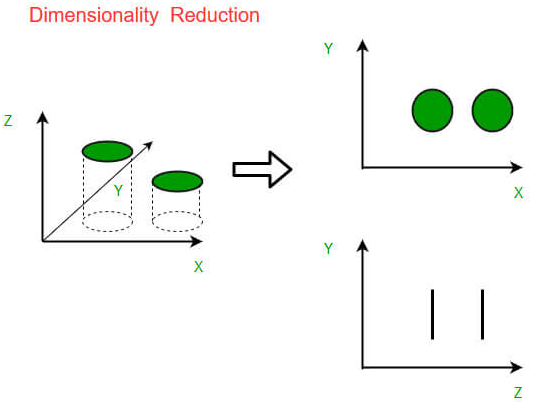
From a technical standpoint, it implies a set of techniques for cutting down the number of input variables in training data.
Unsupervised ML Algorithms: Real Life Examples
k-means Clustering – Document clustering, Data mining
The k-means clustering algorithm is the most popular algorithm in the unsupervised ML operation. It divides the objects into clusters that are similar between them and dissimilar to the objects belonging to another cluster.
In data mining, k-means clustering is used to classify observations into groups of related observations with no predefined relationships.
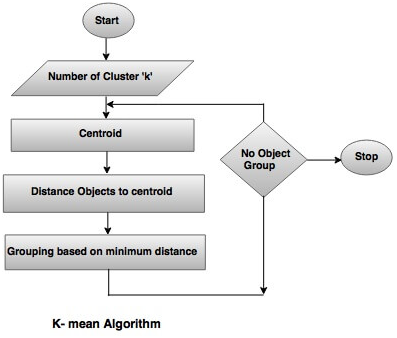
Besides data mining, this tool is in-demand in the following fields:
- Market segmentation;
- Document clustering;
- Image segmentation;
- Pattern recognition;
- Insurance fraud detection and others.
Hidden Markov Model – Pattern Recognition, Bioinformatics, Data Analytics
Today, the need to digitize texts, that is, the need for software that would convert data from paper to digital is ever increasing. Optical character recognition can be used to recognize text from any multimedia, such as image, audio, or video. Hidden Markov Model, in particular, allows you to recognize text or symbols with a high level of accuracy.
In general, HMM is one of the most elaborate ML algorithms. It refers to a statistical model that identifies the evolution of observable events and groups the elements. It’s an invisible Markov chain and each state generates one of the observations, which are visible to us.
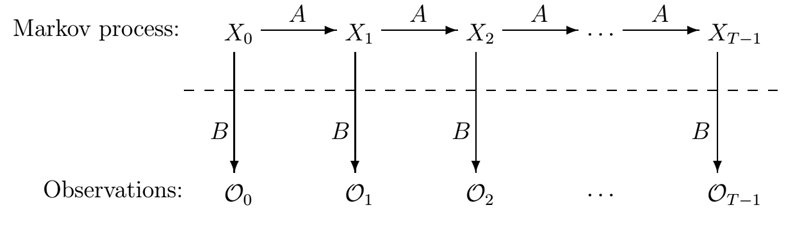
This technology is widely popular and has been applied in various fields from reinforcement learning and temporal pattern recognition to bioinformatics. This algorithm has proved more effective than all competing approaches, which has made it the primary processing paradigm.
HMM use cases also include:
- Computational biology;
- Data analytics;
- Gene prediction;
- Gesture recognition and others.
DBSCAN Clustering – Market research, Data analysis
Density-based spatial clustering of applications with noise or DBSCAN is a popular data clustering algorithm that has found a wide application in data mining and ML. According to a number of points, DBSCAN groups elements that are close to each other distance-wise.
Overall, DBSCAN processing includes the following stages:
- The technology breaks the dataset into dimensions.
- For each data element, the algorithm creates a dimensional shape and then evaluates the number of data points that belong to that shape.
- The shape is then considered a cluster.
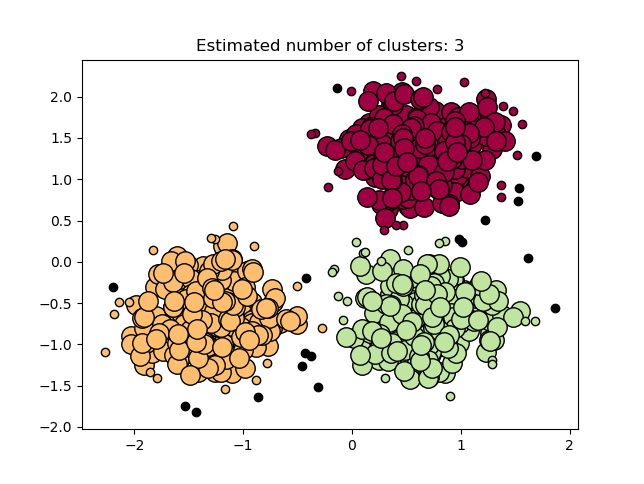
DBSCAN real-life examples include:
- market research;
- pattern recognition;
- data analysis;
- image processing, and others.
Principal Component Analysis (PCA) – Face recognition, Recommendation systems
PCA is a dimensionality-reduction algorithm that is often applied to lessen the dimensionality of huge data sets, by thinning a big set of variables that still retains the valuable information. Principal component analysis may not be the most intricate out of all unsupervised ML algorithms, but it is certainly one of the most important.
Instead of eliminating the features, it groups your input variables in a particular way, thus skipping the least important variables and keeping the most valuable parts.
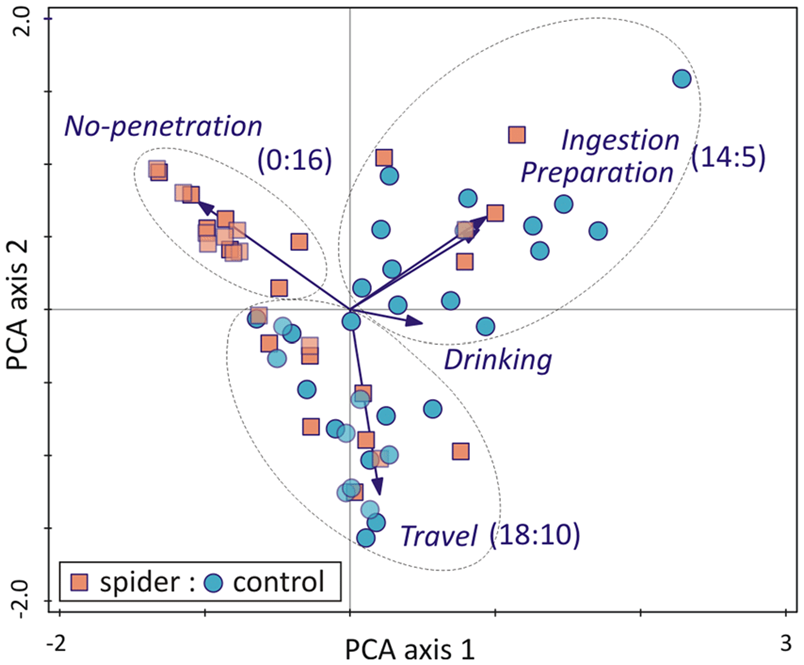
As a visualization tool – PCA is great at showing a bird’s view of the process. It is also applicable in the fields of:
- Face recognition;
- Multivariate data analysis;
- Movie recommendation systems;
- Image compression and others.
t-SNE – Non-linear Visualization Method
T-distributed Stochastic Neighbor Embedding is another unsupervised, randomized algorithm, used only for visualization. Technically, it’s a dimensionality-reduction algorithm that is particularly well-suited for the visualization of high-dimensional datasets. The major advantage of the t-SNE method is that it is non-linear and therefore more visible than the PCA algorithm. Consequently, t-SNE is suited to all sorts of datasets.
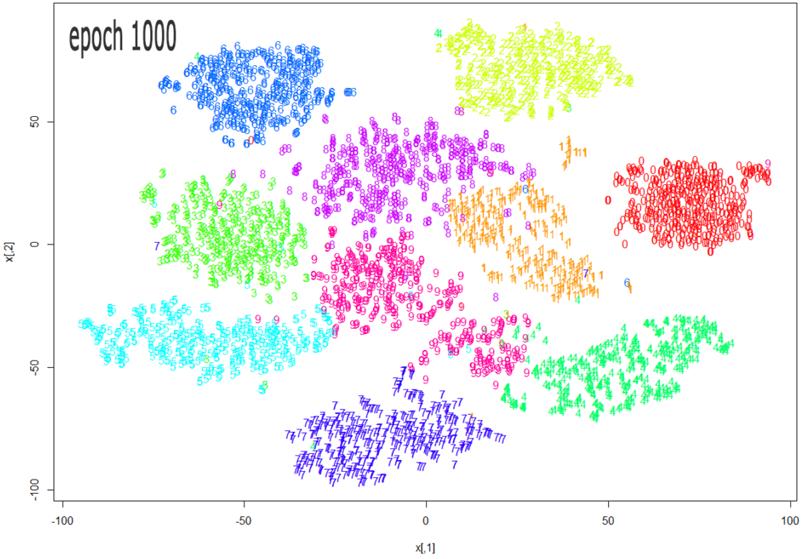
t-SNE has been commonly used for visualizing in a broad spectrum of applications from music analysis and complex audience segmentation to computer security research, cancer research, and bioinformatics.
Singular Value Decomposition (SVD) – Recommender Systems
Singular Value Decomposition (SVD) is an effective method widely used for working with the matrix. Singular Value Decomposition demonstrates the geometric shape of the SVD structure of the matrix and helps visualize the available data.
This algorithm is a go-to tool for solving a wide variety of problems from serving as a least-squares solution to image compression and face recognition. SVD defines prominent data features and makes it suitable for further processing. A great SVD use case is a product recommendation that presents relevant product information to users.
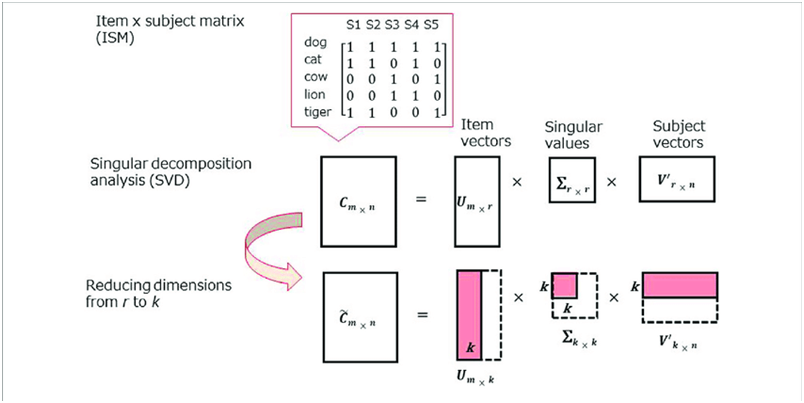
Singular value decomposition is also applicable for:
- Denoising data;
- Fetching particular types of information from the dataset (for instance, finding info on every user located in LA);
- Making suggestions for a particular user (recommender engine).
Association Rule – Market basket analysis
Association rule is one of the core methods of unsupervised ML. Initially, it was used to find typical purchase patterns in supermarkets – market basket analysis.
In other words, the purpose of the association rule is to uncover how items are associated with each other. In the end, it boils down to a simple and popular market formula – people who bought X, also bought Y.
Therefore, the association rule is a staple market tool that allows to:
- optimize product placement;
- formulate customized product suggestion;
- plan promotional campaigns;
- improve merchandise planning and price optimization.
The Bottom Line
Machine learning has already become a robust tool for pulling out actionable business insights. However, as ML algorithms vary tremendously, it is crucial to understand how unsupervised algorithms work to successfully automate parts of your business. We hope that this article has helped you get a foot in the door of unsupervised machine learning.








{kind=link}