
Organizations should consider multiple aspects of deploying big data analytics. These include the type of analytics to be deployed, how the analytics will be deployed technologically and who must be involved both internally and externally to enable success. Our recent big data analytics benchmark research assesses each of these areas.
Organizations should consider multiple aspects of deploying big data analytics. These include the type of analytics to be deployed, how the analytics will be deployed technologically and who must be involved both internally and externally to enable success. Our recent big data analytics benchmark research assesses each of these areas. How an organization views these deployment considerations may depend on the expected benefits of the big data analytics program and the particular business case to be made, which I discussed recently.
According to the research, the most important capability of big data analytics is predictive analytics (64%), but among companies 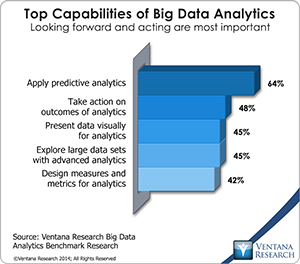 that have deployed big data analytics, descriptive analytic approaches of query and reporting (74%) and data discovery (64%) are more readily available than predictive capabilities (57%). Such statistics may be a function of big data technologies such as Hadoop, and their associated distributions having prioritized the ability to run descriptive statistics through standard SQL, which is the most common method for implementing analysis on Hadoop. Cloudera’s Impala, Hortonworks’ Stinger (an extension of Apache Hive), MapR’s Drill, IBM’s Big SQL, Pivotal’s HAWQ and Facebook’s open-source contribution of Presto SQL all focus on accessing data through an SQL paradigm. It is not surprising then that the technology research participants use most for big data analytics is business intelligence (75%) and that the most-used analytic methods — pivot tables (46%), classification (39%) and clustering (37%) — are descriptive and exploratory in nature. Similarly, participants said that visualization of big data allows analysts to perform faster analysis (49%), understand context better (48%), perform root-cause analysis (40%) and display multiple result sets (40%), but visualization does not provide more advanced analytic capabilities. While various vendors now offer approaches to run advanced analytics on big data, the research shows that in terms of big data, organizational capabilities still revolve around more basic analytic access.
that have deployed big data analytics, descriptive analytic approaches of query and reporting (74%) and data discovery (64%) are more readily available than predictive capabilities (57%). Such statistics may be a function of big data technologies such as Hadoop, and their associated distributions having prioritized the ability to run descriptive statistics through standard SQL, which is the most common method for implementing analysis on Hadoop. Cloudera’s Impala, Hortonworks’ Stinger (an extension of Apache Hive), MapR’s Drill, IBM’s Big SQL, Pivotal’s HAWQ and Facebook’s open-source contribution of Presto SQL all focus on accessing data through an SQL paradigm. It is not surprising then that the technology research participants use most for big data analytics is business intelligence (75%) and that the most-used analytic methods — pivot tables (46%), classification (39%) and clustering (37%) — are descriptive and exploratory in nature. Similarly, participants said that visualization of big data allows analysts to perform faster analysis (49%), understand context better (48%), perform root-cause analysis (40%) and display multiple result sets (40%), but visualization does not provide more advanced analytic capabilities. While various vendors now offer approaches to run advanced analytics on big data, the research shows that in terms of big data, organizational capabilities still revolve around more basic analytic access.
For companies that are implementing advanced analytic capabilities on big data, there are further analytic process considerations, and many have not yet tackled those. Model building and model deployment should be manageable and timely, involve specialized personnel, and integrate into the broader enterprise architecture. While our research provides an in-depth look at adoption of the different types of in-database analytics, deployment of advanced analytic sandboxes, data mining, model management, integration with business processes and overall model deployment, that is beyond the topic here.

Beyond analytic considerations, a host of technological decisions must be made around big data analytics initiatives. One of these is the degree of customization necessary. As technology advances, customization is giving way to more packaged approaches to big data analytics. According to our research, the majority (54%) of companies that have already implemented big data analytics did custom builds using big data-specific languages and interfaces. The most of those that have not yet deployed are likely to purchase a dedicated or packaged application (44%), followed by a custom build (36%). We think that this pre- and post-deployment comparison reflects a maturing market.
must be made around big data analytics initiatives. One of these is the degree of customization necessary. As technology advances, customization is giving way to more packaged approaches to big data analytics. According to our research, the majority (54%) of companies that have already implemented big data analytics did custom builds using big data-specific languages and interfaces. The most of those that have not yet deployed are likely to purchase a dedicated or packaged application (44%), followed by a custom build (36%). We think that this pre- and post-deployment comparison reflects a maturing market.
The move from custom approaches to standardized ones has important implications for the skills sets needed for a big data  analytics initiative. In comparing the skills that organizations said they currently have to the skills they need to be successful with big data analytics, it is clear that companies should spend more time building employees’ statistical, mathematical and visualization skills. On the flip side, organizations should make sure their tools can support skill sets that they already have, such as use of spreadsheets and SQL. This is convergent with other findings about training needs, which include applying analytics to business problems (54%), training on big data analytics tools (53%), analytic concepts and techniques (46%) and visualizing big data (41%). The data shows that as approaches become more standardized and the market focus shifts toward them from customized implementations, skill needs are shifting as well. This is not to say that demand is moving away from the data scientist completely. According to our research, organizations that involve cross-functional teams or data scientists in the deployment process are realizing the most significant impact. It is clear that multiple approaches for personnel, departments and current vendors play a role in deployments and that some approaches will be more effective than others.
analytics initiative. In comparing the skills that organizations said they currently have to the skills they need to be successful with big data analytics, it is clear that companies should spend more time building employees’ statistical, mathematical and visualization skills. On the flip side, organizations should make sure their tools can support skill sets that they already have, such as use of spreadsheets and SQL. This is convergent with other findings about training needs, which include applying analytics to business problems (54%), training on big data analytics tools (53%), analytic concepts and techniques (46%) and visualizing big data (41%). The data shows that as approaches become more standardized and the market focus shifts toward them from customized implementations, skill needs are shifting as well. This is not to say that demand is moving away from the data scientist completely. According to our research, organizations that involve cross-functional teams or data scientists in the deployment process are realizing the most significant impact. It is clear that multiple approaches for personnel, departments and current vendors play a role in deployments and that some approaches will be more effective than others.
Cloud computing is another key consideration with respect to deploying analytics systems as well as sandbox modelling and testing environments. For deployment of big data analytics, 27 percent of companies currently use a cloud-based method, while 58 percent said they do not and 16 percent do not know what is used. Not surprisingly, far fewer IT professionals (19%) than business users (40%) said they use cloud-based deployments for big data analytics. The flexibility and capability that cloud resources provide is particularly attractive for sandbox environments and for organizations that lack big data analytic expertise. However, for big data model building, most organizations (42%) still utilize a dedicated internal sandbox environment to build models while fewer (19%) use a non-dedicated internal sandbox (that is, a container in a data warehouse used to build models) and others use a cloud-based sandbox either as a completely separate physical environment (9%) or as a hybrid approach (9%). From this last data we infer that business users are sometimes using cloud-based systems to do big data analytics without the knowledge of IT staff. Among organizations that are not using cloud-based systems for big data analytics, security (45%) is the primary reason that they do not.
Perhaps the most important consideration for big data analytics is choosing vendors to partner with to achieve organizational objectives. When we understand the move from custom technological approaches to more packaged ones and the types of analytics currently being implemented for big data, it is not surprising that a majority of research participants (52%) are looking to their business intelligence systems providers to supply their big data analytics solution. However, a significant number of companies (35%) said they will turn to a specialist analytics provider or their database provider (34%). When evaluating big data analytics, usability is the most important vendor consideration but not by as wide a margin as in categories such as business intelligence. A look at criteria rated important and very important by research participants reveals usability is the highest ranked (94%), but functionality (92%) and reliability (90%) follow closely. Among innovative new technologies, collaboration is important (78%) while mobile access (46%) is much less so. Coupled with the finding that communication and knowledge sharing combined is an important benefit of big data analytics, it is clear that organizations are cognizant of the collaborative imperative when choosing a big data analytics product.
Deployment of big data analytics starts with forethought and a well-defined business case that includes the expected benefits I discussed in my previous analysis. Once the outcome-driven framework is established, organizations should consider the types of analytics needed, the enabling technologies and the people and processes necessary for implementation. To learn more about our big data analytics research, download a copy of the executive summary here.





