
|
My presentation on the 7th annual text analytics summit was a tutorial in one of the methodologies one could use to analyze unstructured text. The sample consisted of 365000 tweets that contained keywords of Apple products and concepts such as iPad, iPhone, iPod, Apple Store, Mac, Steve Jobs and the goal was to get an understanding of what people where tweeting about each product or concept.
The first step is to use a text analysis toolkit (i used GATE) to annotate the tweets and identify which concepts and keywords occur within the tweets. But this is not always easy. Take the word Mac for example. According to the context, Mac could be a computer type, a burger type, the MAC beauty products or Mac Arthur airport. So when a query sent to Twitter API that contains the word Mac we end up with lots of erroneous information.
So one of the things that have to be done to ensure good results is word sense disambiguation. We know for example that if a tweet contains a word such as fries, lettuce and/or salad then quite likely the word Mac that was also found within this tweet was about the Big Mac (even though the word Big may not be present). If we find the word Arthur next to the word Mac then the tweet is about the Mac Arthur airport, etc. Here is GATE in action, identifying different keywords and concepts in Tweets :
|

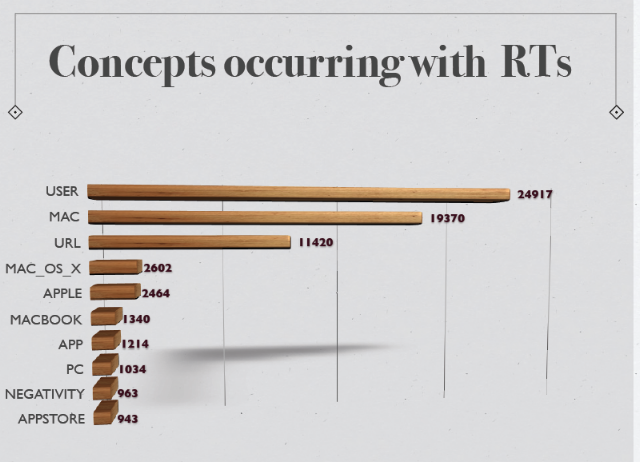
Now we can see which concepts and keywords appear frequently in Re-Tweets (‘USER’ denotes that a ‘@’ was present in the Tweet, ‘URL’ that a URL link was found in the Tweet,etc)
We can also see which words frequently occur with iPhone5 :




